广义估计方程(GEE)的SPSS操作教程
2017-05-14 医伽会 医伽会
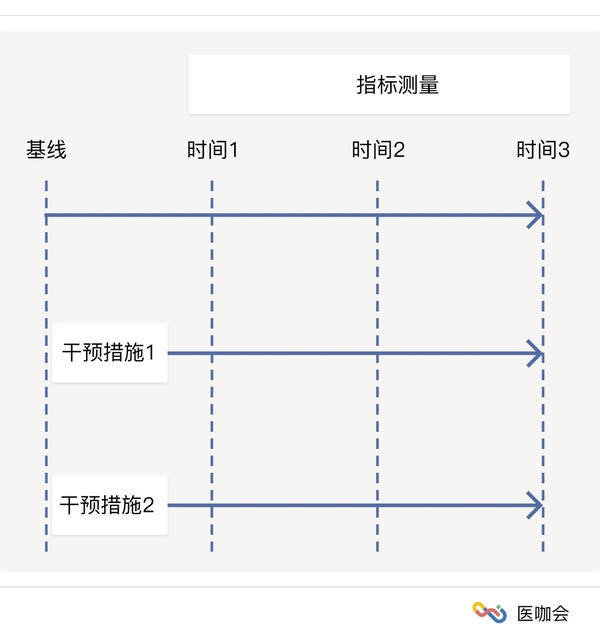
在临床研究中,经常会比较两种治疗方式对患者结局的影响,并且多次测量结局。例如,为了研究两种降压药物对血压的控制效果是否存在差异,研究者会对两个人群服药后在不同时间点记录血压值,然后评价降压效果。或者对两组动物分别施加两种干预,连续记录多个时间点的结局,然后比较两种干预的效果。 这种设计可以用如下示意图表示: 另外,有时研究只需要收集一个时间点的数据,但是一个研究对象会提供多个部位的数据
在临床研究中,经常会比较两种治疗方式对患者结局的影响,并且多次测量结局。例如,为了研究两种降压药物对血压的控制效果是否存在差异,研究者会对两个人群服药后在不同时间点记录血压值,然后评价降压效果。或者对两组动物分别施加两种干预,连续记录多个时间点的结局,然后比较两种干预的效果。 这种设计可以用如下示意图表示: 另外,有时研究只需要收集一个时间点的数据,但是一个研究对象会提供多个部位的数据点。例如,研究者想评价冠心病患者在冠脉搭桥术后应用阿司匹林是否可以有效降低患者血管的再堵塞,评价的方法是术后1年做冠脉造影观察血管是否堵塞,但是每个患者可能会在同一次手术中对多条冠状动脉血管进行搭桥,因此有的患者可能会贡献多组数据。 这种设计可以用如下示意图表示: 以上两种设计,不管是临床试验还是动物试验都非常常见,它的特点在于数据间非独立,同一个体间数据具有相关性。对于这样的设计类型,该如何分析呢? 今天我们来介绍另外一种非常好的方法——广义估计方程(GEE)。GEE既可以处理连续型结局变量也可以处理分类型结局变量,它实际上代表了一种模型类别,即在传统模型的基础上对相关性数据进行了校正,可以拟合Logi
作者:医伽会
版权声明:
本网站所有注明“来源:梅斯医学”或“来源:MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明“来源:梅斯医学”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
小提示:本篇资讯需要登录阅读,点击跳转登录





按步骤输入,显示警告:至少有两个记录具有相同的主体变量值和主体内变量值,将不会显出任何输出,停止执行该命令,这是哪里出问题了啊?
4
请问SPSS中设置好模型后点运行后出现警告:There are at least two records with the same values for the subject and within-subject variables. 这是怎么回事呢?
53
怎么才可以看全文嘛!!拜托拜托,想看全文啊大哭
124
宝贵的学习资源,谢谢分享
92
学习了受益匪浅
102