有序多分类Logistic回归SPSS实战操作教程
2017-05-12 MedSci MedSci原创
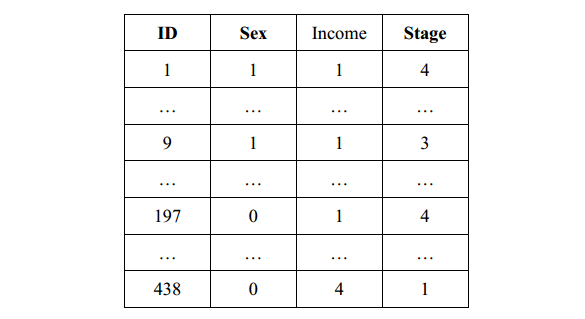
1、问题与数据 在某胃癌筛查项目中,研究者想了解首诊胃癌分期(Stage)与患者的经济水平的关系,以确定胃癌筛查的重点人群。为了避免性别因素对结论的混杂影响,研究者将性别(Sex)也纳入分析(本例仅为举例说明如何进行软件操作,实际研究中需控制的混杂因素可以更多)。研究者将所有筛查人群的结果如表1,变量赋值如表2。 表1. 原始数据 表2. 变量赋值情况 2、对数据结构的分析
1、问题与数据 在某胃癌筛查项目中,研究者想了解首诊胃癌分期(Stage)与患者的经济水平的关系,以确定胃癌筛查的重点人群。为了避免性别因素对结论的混杂影响,研究者将性别(Sex)也纳入分析(本例仅为举例说明如何进行软件操作,实际研究中需控制的混杂因素可以更多)。研究者将所有筛查人群的结果如表1,变量赋值如表2。 表1. 原始数据 表2. 变量赋值情况 2、对数据结构的分析 该设计中,因变量为四分类,且分类间有次序关系,针对因变量为分类型数据的情况应该选用Logistic回归,故应采用有序多分类的Logistic回归分析模型进行分析。 有序多分类的Logistic回归原理是将因变量的多个分类依次分割为多个二元的Logistic回归,例如本例中因变量首诊胃癌分期有1-4期,分析时拆分为三个二元Logistic回归,分别为(1 vs 2+3+4) 、(1+2 vs 3+4)、(1+2+3 vs 4),均是较低级与较高级对比。需注意的是,有序多分类Logistic回归的假设是,拆分后的几个二元Logistic回归的自变量系数相等,仅常数项不等。其结果也只输出一组自变量的系数。 因此,有序多分
作者:MedSci
版权声明:
本网站所有注明“来源:梅斯医学”或“来源:MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明“来源:梅斯医学”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
小提示:本篇资讯需要登录阅读,点击跳转登录






qw请问我数值型变量转换成有序变量.划分的节点怎么定.可以算出来还是自己随便定义?谢谢
121
#Logistic#
75
#logistic回归#
72
学习了谢谢分享
102
有用,谢谢
108