使用SPSS实现1:1倾向性评分匹配(PSM)
2017-10-19 医咖会 医咖会
谈起临床研究,如何设立一个靠谱的对照,有时候成为整个研究成败的关键。对照设立的一个非常重要的原则就是可比性,简单说就是对照组除了研究因素外,其他的因素应该尽可能和试验组保持一致,这里就不得不提随机对照试验。众所周知,随机对照试验中研究对象是否接受干预是随机的,这就保证了组间其他混杂因素均衡可比。但是有些时候并不能实现随机化,比如说观察性研究。这时候倾向性评分匹配(propensity scor
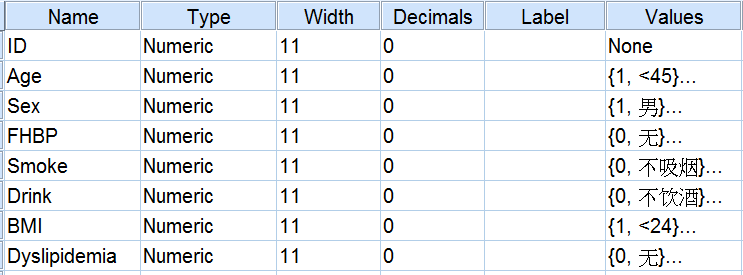
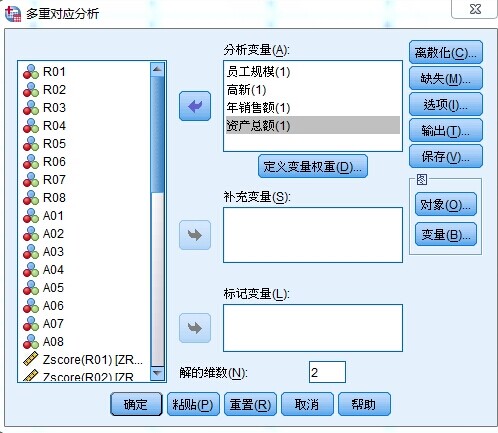
谈起临床研究,如何设立一个靠谱的对照,有时候成为整个研究成败的关键。对照设立的一个非常重要的原则就是可比性,简单说就是对照组除了研究因素外,其他的因素应该尽可能和试验组保持一致,这里就不得不提随机对照试验。众所周知,随机对照试验中研究对象是否接受干预是随机的,这就保证了组间其他混杂因素均衡可比。但是有些时候并不能实现随机化,比如说观察性研究。这时候倾向性评分匹配(propensity score matching, PSM)可以有效降低混杂偏倚,并且在整个研究设计阶段,得到类似随机对照研究的效果。与常规匹配相比,倾向性评分匹配能考虑更多匹配因素,提高研究效率。这么“高大上”的倾向性评分匹配,是不是超级难学?错矣!今天就带大家轻松搞定1:1倾向性评分匹配。作为“稀罕”大招,并不是在所有版本的SPSS都可以实现倾向性评分匹配,仅在SPSS22及以上自带简易版PSM,对于其他版本或者想要体验完整版功能,就不得不去安装相应的软件(R软件、SPSS R插件、PS matching插件。。。超级难安装!那是需要运气和耐心的!)。本次使用SPSS 22为大家演示1:1倾向性评分匹配。一、问题与数据某
作者:医咖会
版权声明:
本网站所有注明“来源:梅斯医学”或“来源:MedSci原创”的文字、图片和音视频资料,版权均属于梅斯医学所有。非经授权,任何媒体、网站或个人不得转载,授权转载时须注明“来源:梅斯医学”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。
在此留言
小提示:本篇资讯需要登录阅读,点击跳转登录




逆概率加权能做吗
5
请问老师SPSS哪个版本可以做倾向性评分?
8
非常感谢 讲的很详细
72
请问三组的匹配怎么操作?就直接多加一组数据么?
66
讲的太清楚了.谢谢
68